
AI in Saudi Arabia Healthcare: Use Cases & Current Regulatory Landscape
13 Views 7 min July 31, 2026

Reena Bhagat, the CTO and Head of AI at Apptunix, is a seasoned technology strategist with a deep-rooted expertise in emerging technologies. With a focus on AI/ML integration, product engineering, cloud management, she leads the technical vision for high-performance SaaS infrastructures. Reena is recognized for building secure, scalable, and decentralized systems that solve real-world complexities. Her passion lies in leveraging data science and future-tech to create resilient digital products, making her a trusted authority for organizations looking to lead in the age of intelligent automation.

The global artificial Intelligence (AI) market is expected to soar to $1.85 trillion by 2030. Without a doubt, artificial intelligence (AI) is the driving force behind powering the digital revolution across all industries and businesses.
One of the most remarkable advances in AI is the Multimodal AI concept. Research suggests that the global multimodal AI industry is expected to reach $4.5 billion at a compound annual growth rate of 35.0% by 2028.
The multimodal AI model approach has completely refined how we interact with technology. Its ability offers personalized, real-time responses fostering connections that resonate on a human level.
In today’s detailed guide, we’ll delve into multimodal AI, including working, advantages, uses, and more. Let’s get started!
Multimodal artificial intelligence (AI) is an advanced form of artificial intelligence that can understand and interpret multiple data types such as text, images, and audio.
It combines data from various sources and generates contextually relevant information using neural network topologies.
Various industries, including healthcare, multimedia production, virtual assistants, and creative design, can benefit from the application of this technology.
Ultimately, these models yield deep learning techniques and insights to generate accurate outputs and insights.
Example:
Multimodal AI is best demonstrated by virtual assistants such as Google Assistant and Alexa from Amazon. These assistive technologies can respond to commands verbally (audio modality), visually (visual modality), and provide text-based responses (text modality).
To give customers a smooth and simple experience, these virtual assistants manage data from multiple modalities and carry out activities like reminding consumers and managing smart home appliances.

The first thing that comes to mind when we hear the term “AI” is of robots or machines, right? But what if you’re looking for natural and contextual conversation more human-like – that’s when multimodal AI approach comes in. It enhances communication with AI models by incorporating multiple input modes such as text, images, voice, and video.
In today’s modern communication landscape, we rely on various sources to seamlessly process information. Think about how you interact with your friends and family on smartphones – switching effortlessly between text, images, videos, or audio. Each medium or channel offers valuable context to comprehend the information.
Multimodal Artificial intelligence enables AI systems such as chatbots and virtual assistants, to understand and respond to users more naturally and intuitively.
It helps to enhance the user experience and boost the effectiveness and efficiency of interactions across a variety of sectors.
Multimodal AI offers new opportunities for creativity and problem-solving by leveraging multiple modalities. It eventually propels breakthroughs in artificial intelligence and its applications.
Following, we’ve discussed 3 key components of Multimodal AI. It includes –
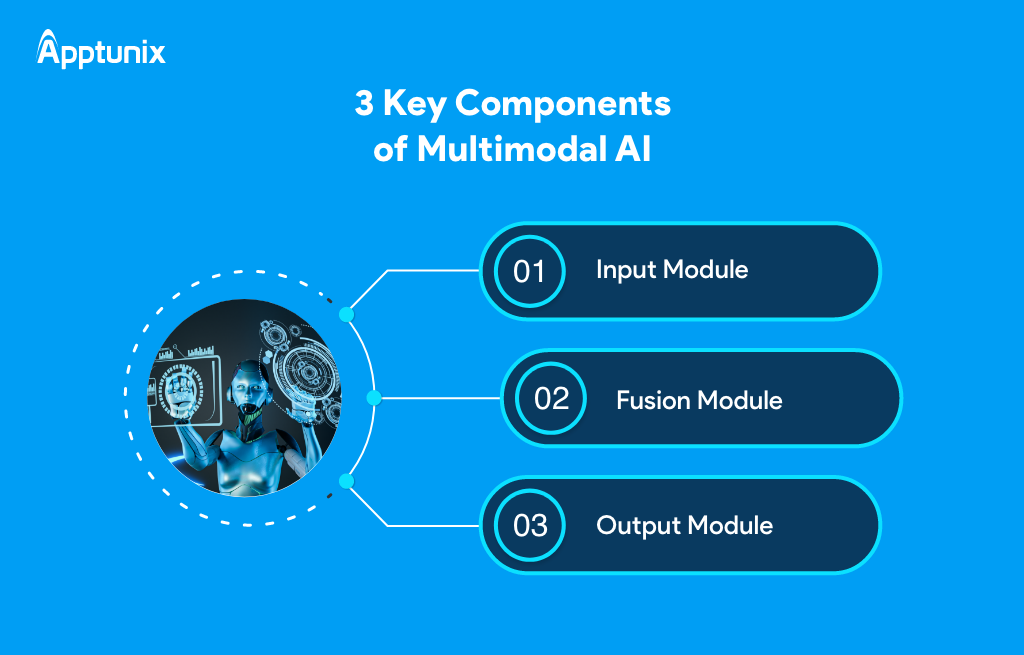
1. Input ModuleThis module serves as the AI’s sensory system, gathering various data types, such as text, images, and more. It prepares the data for subsequent processing by the AI.
2. Fusion ModuleConsider this as the AI’s central processing unit, intelligently combining all the facts it has gathered. It compiles data from several sources and applies state-of-the-art techniques to highlight important details and create a coherent image.
3. Output ModuleThis module provides the final output, much like the AI’s mouth does. Following the Fusion Module’s processing of the data, the user is presented with the AI’s conclusions or responses via the output module.
Read More: AI in Logistics: Benefits, Use Cases, & Challenges!
Let’s understand how the system of multimodal artificial intelligence works –
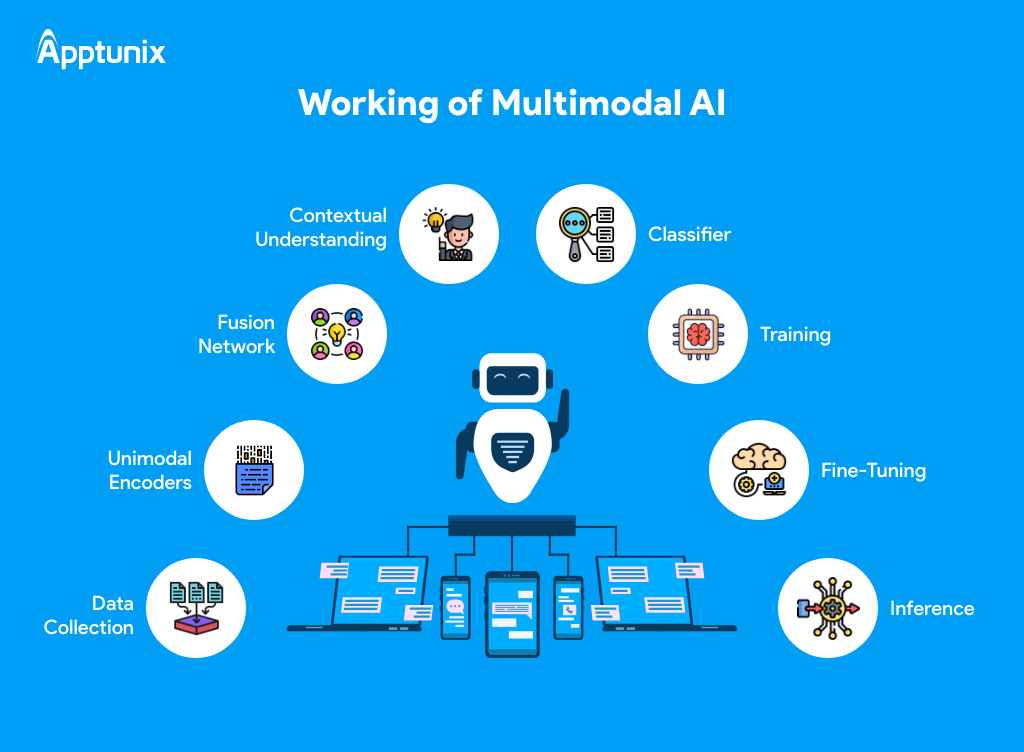
It begins by gathering data from various sources, such as text, images, audio, or other modalities.
Each modality’s data is processed separately by specialized encoders extracting relevant features from the input data.
The extracted features from different modalities are combined in a fusion network, which integrates the information into a unified representation.
The fusion network considers the context of the input data to understand the relationships between different modalities and their significance.
After contextual understanding, a classifier makes predictions or classifications based on the fused multimodal representation.
The Multimodal AI system is trained using labeled data to learn the relationships between different modalities and improve its predictive capabilities.
Fine-tuning involves adjusting the parameters of the Multimodal AI model to optimize its performance on specific tasks or datasets.
Once trained and fine-tuned, the Multimodal Artificial intelligence model can be used for inference, making predictions or classifications on new, unseen data inputs.
Recommended Read: AI-Powered Software Development: Benefits and Use Cases
Multimodal AI is used across multiple industries, offering transformative changes. Following, we’ve discussed in detail:
1. Gesture RecognitionThese models are essential to translating sign language because they can identify and comprehend human gestures. By translating gestures into text or speech, multimodal models facilitate inclusive communication and the closing of communication gaps.
2. Visual Question Answering (VQA)Multimodal models combine natural language processing and visual understanding to respond to questions about images effectively. This feature is handy for instructional platforms, interactive systems, and other applications.
3. Video SummarizationThe Multimodal Artificial intelligence model facilitates video summarization by extracting audio and visual characteristics. It speeds up content consumption, improves video content management systems, and makes browsing more efficient.
4. Medical DiagnosisMultimodal AI assists in medical diagnosis by combining data from various sources. It includes patient records, medical scans, and textual reports. Further, it aids doctors and medical professionals diagnose and formulate effective patient treatment plans and improve patient care.
5. Educational ToolsMultimodal models enhance learning experiences by providing dynamic instructional content that responds to students’ verbal and visual inputs.
They play a crucial role in adaptive learning systems, which dynamically adjust the course content and degree of difficulty in response to student performance and feedback.
6. Autonomous VehicleThe development of multimodal models is essential to the evolution of autonomous vehicles. To navigate and identify risks, these vehicles analyze data from radar, cameras, LiDAR, sensors, and GPS. They then make decisions about how to drive in real-time. This technology is required to produce safe and dependable autonomous vehicles.
7. Image CaptioningMultimodal models produce descriptions for images, demonstrating a profound understanding of both visual and linguistic information. They are essential for content recommendation, automatic image labeling, and improving accessibility for those with visual impairments.
8. Emotion RecognitionMultimodal AI can detect and understand human emotions from certain sources, including voice tone, text sentiment, and facial expressions. It assists in sentiment analysis on social media and the mental health support system to gauge and respond to users’ emotional support.
9. DALL-E–Text-to-Image GenerationDALL-E is a multimodal artificial intelligence variant that helps generate images from text descriptions. It assists in advertising, art, design, and more.
10. Virtual AssistantsMultimodal AI helps to understand and respond to voice commands while processing visual data for a comprehensive user interaction. They assist in voice-controlled devices, digital personal assistants, and smart home automation.
Also Read: Top 10 AI & Automation Trends Every Enterprise Should Prepare for in 2026
Following, we’ve discussed various benefits of Multimodal AI. Let’s discuss:

1. Improved AccuracyMultimodal artificial intelligence (AI) can accomplish greater accuracy in tasks like speech recognition, sentiment analysis, and object recognition by utilizing the complementary features of many modalities.
2. Natural InteractionMultimodal AI enables inputs from multiple modalities, including speech, gestures, and facial expressions, thereby improving user experiences. It improves the communication and intuition of human-machine interaction.
3. Enhanced UnderstandingComprehending context is a unique skill for multimodal models, and it’s necessary for tasks like responding correctly and to understand spoken language. They combine textual and visual data analysis to achieve this.
This contextual awareness is also helpful for conversation-based systems. By using both textual and visual inputs, multimodal models can produce replies with a more human-like feel.
4. RobustnessMultimodal AI reduces the influence of noise or mistakes in individual modalities and is therefore more resilient to changes and uncertainties in data since it may draw from multiple sources of information to produce predictions or classifications.
5. Enhanced CapabilityMultimodal models enable significantly more powerful AI systems. They make use of information from a variety of sources, such as text, images, audio, and video, to enhance their comprehension of the world and its context.
Bonus Read: Generative AI Software Development: Benefits, Possibilities, and Cost Involved
Let’s go through various use cases of Multimodal AI:

1. Human-Computer InteractionMultimodal AI processes inputs from several modalities, including speech, gestures, and facial expressions, to enable more intuitive and natural interactions between humans and computers.
2. Weather ForecastingMultimodal AI is capable of analyzing data from multiple sources, including satellite imagery, weather sensors, and historical data, to produce precise weather forecasts.
3. HealthcareMultimodal models help in medical image analysis in the healthcare industry by merging information from multiple sources, including written reports, medical scans, and patient records. Ultimately, they improve patient care by helping medical practitioners make precise diagnoses and create efficient treatment regimens.
Bonus Read: AI in Healthcare: Benefits, Applications, and Cases
4. Language TranslationMultimodal artificial intelligence system can translate spoken words from one language into another and back again while taking gestures, facial expressions, and other speech-related contextual cues into account to provide more accurate translations.
5. Sensory Integration DevicesMultimodal artificial intelligence (AI) powers devices that integrate touch, visual, and auditory inputs to enhance user experiences in augmented reality, virtual reality, and assistive technology.
6. Multimedia Content CreationMultimodal AI can create multimedia content by combining inputs from several modalities. It includes text descriptions, audio recordings, and visual references. This allows for automated content creation procedures.
Following, we’ve discussed the difference between Unimodal AI and Multimodal AI. Let’s discuss:

There are certain challenges involved in Multimodal Artificial intelligence system. Let’s discuss:
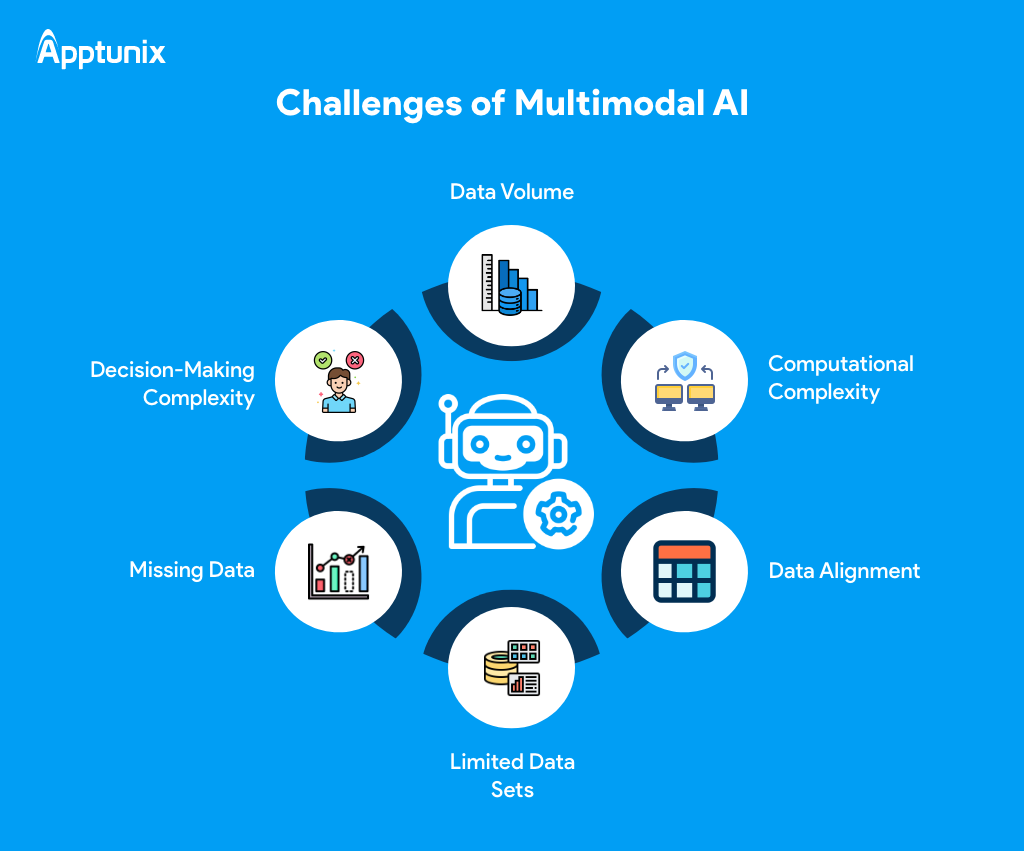
1. Data VolumeMultimodal AI needs massive volumes of data from multiple modalities for training and learning to be effective, but this can be challenging to obtain and manage.
2. Computational ComplexityIt can be computationally demanding to process and analyze data from several modalities at once, necessitating strong hardware and effective algorithms.
3. Data AlignmentAligning data from different modalities in a way can be challenging due to differences in format, timing, and semantics.
4. Limited Data SetsThe performance of multimodal AI models and their capacity to generalize to new tasks or domains may be hampered by the restricted availability of labeled data for training.
5. Missing DataHandling missing data across different modalities challenges maintaining model accuracy and robustness.
6. Decision-Making ComplexityDecision-making processes get more complex when information from several modalities is integrated, necessitating the use of complex frameworks and algorithms for efficient reasoning and inference.
Partnering with Apptunix, a leading AI development company dedicated to quality and innovation, will help you realize the full potential of multimodal artificial intelligence.
Our ability to create cutting-edge solutions lets businesses fully utilize Multimodal artificial intelligence’s revolutionary potential, revolutionizing their online presence and enhancing user experiences.
Now is the time to collaborate with Apptunix to embark on a profitable, cutting-edge technological journey. Get in touch with experts today!

Q 1.What is the difference between Multimodal AI and generative AI?
Multimodal AI integrates multiple data types, such as text, images, and audio, to understand and generate content. On the other hand, generative AI creates new content based on learned patterns or examples.
Q 2.Is ChatGPT a multimodal AI?
The ChatGPT interface can provide a genuine multimodal experience since the AI can decide which modules are appropriate to use at any given moment.
Q 3.What is a Multimodal generative model?
A Multimodal generative model is an AI model that can generate content across multiple modalities, such as describing audio clips or generating captions for images.
Q 4.Can I use Multimodal AI for content creation?
Yes, Multimodal AI can be used for content creation. It combines different types of data to generate diverse and rich content, including text, images, and audio.
Get the weekly updates on the newest brand stories, business models and technology right in your inbox.
Reena Bhagat, the CTO and Head of AI at Apptunix, is a seasoned technology strategist with a deep-rooted expertise in emerging technologies. With a focus on AI/ML integration, product engineering, cloud management, she leads the technical vision for high-performance SaaS infrastructures. Reena is recognized for building secure, scalable, and decentralized systems that solve real-world complexities. Her passion lies in leveraging data science and future-tech to create resilient digital products, making her a trusted authority for organizations looking to lead in the age of intelligent automation.
13 Views 7 min July 31, 2026

47 Views 7 min July 21, 2026

99 Views 7 min July 2, 2026
Book your consultation with us.
Book your consultation with us.
One Central, The offices 3, Level 3, DWTC, Sheikh Zayed Road, Dubai
+971 50 782 1690
Offer Ends Soon
Get a quick expert response in under 5 minutes.











